


はじめに
B4の諸隈です.2024年9月2日~4日に北海道情報大学で開催された,Entertainment Computing 2024で行った研究発表について報告いたします.
「琵琶湖周辺に生息するクマはひょんなことから北海道で魚介を食らう」というタイトルで発表しました.
研究概要
この研究では,真実性と想像の多様性に着目した「ひょんなことから要約」を用いたキャッチフレーズの自動生成について検討しました.
現在,読書意欲を促進させるような要約の自動生成は未だ確立されておらず,大手小説投稿サイトでも作者自身が考案したあらすじが掲載されています.そこで今回ひょんなことから要約という,読者の興味を惹くキャッチフレーズの自動生成を目指しています.ひょんなことから要約とは,下図のように物語を論理的に構造化・創作する手法であり,漫画家うめの小沢高広氏が講師やインタビュー等で紹介しています. 例えば,桃太郎を要約すると「桃から生まれた桃太郎は犬,猿,雉をお供に村を苦しめる鬼を退治する」となりますが,ひょんなことから要約も用いると「桃から生まれた桃太郎はひょんなことから鬼を退治する」となります.ひょんなことから要約では,経緯について「ひょんなことから」で秘匿することで「どうして?」「どうやって?」と読者が多様な想像をすることが,読者の興味を惹くことに繋がると考えています. そこで今回は,物語の要点のみを提示して経緯を秘匿するひょんなことから要約のキャッチフレーズ生成に取り組みました.
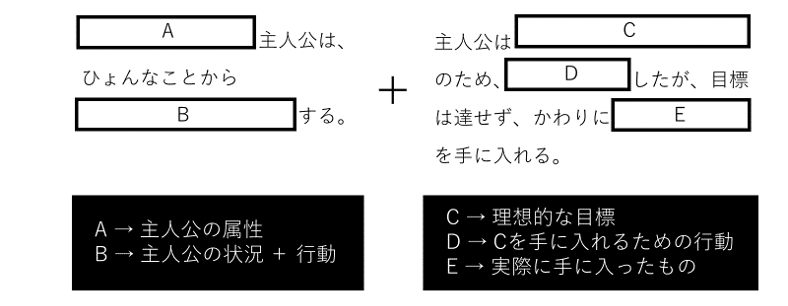
研究の背景
キャッチフレーズというのは,作品の要約によっても生成することが出来ます.自動要約を目的として,整合性に着目した物語要約や重要語の抽出による要約など,様々な技術が報告されています.一方で読書意欲を促進させるような要約の自動生成は未だ確立されておらず,大手小説投稿サイトでも作者自身が考案したあらすじを掲載しています.その理由として,多くの研究では正しさやネタバレなどネガティブな要素を最小限にする取り組みを行っており,肝心の読者の興味を惹くという要素を満たすことが出来ていないということが考えられます.そこで本研究ではネタバレや真実性などネガティブな要素に加えて想像の多様性という読者の興味を惹く要素を取り入れています.
具体的な手法
ひょんなことから要約の自動生成する手順は下図のような3Phaseに分けることが出来ます.まず,Phase 1 では,ひょんなことから要約の構成パーツおよび秘匿部に相当する事象を生成します.Phase 2では,Phase 1 で秘匿部に相当する事象として生成した「真の経緯」「疑似経緯」を用いて,同様に Phase 1 で生成した「A: 主人公属性」「B: 主人公の状況/行動」を真実性と多様性の観点からそれぞれ評価します.Phase 3 では,Phase 2での評価値が高かった「A: 主人公属性」と「B: 主人公の状況/行動」を組み合わせてひょんなことから要約文を生成します.以下に各節でそれぞれの Phase の詳細を示します.
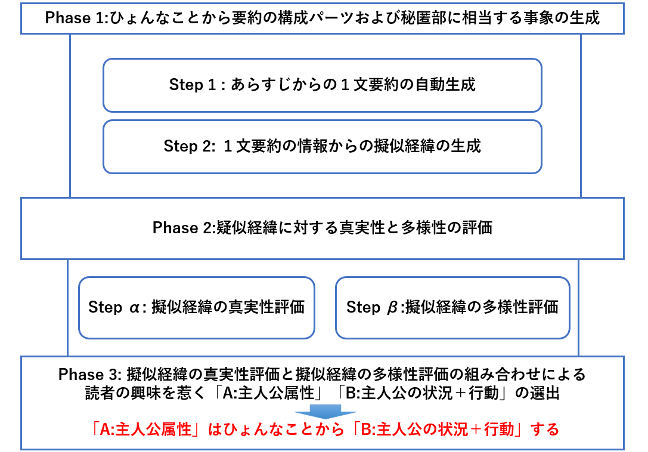
Phase1: ひょんなことから要約の構成パーツおよび秘匿部に相当する事象の生成 Phase 1 の処理は,Step 1 と Step 2から構成されています.まず,Step 1 ではあらすじ文を入力として,GPT-4o に下図のプロンプトで指示することでひょんなことから要約の 1 文目である「【A】主人公はひょんなことから【B】する.」の形式での 1 文要約を n 個生成します.これにより,A,B,および A が B となる真の経緯がそれぞれ獲得されます.

Step 2 では,Step 1 で生成した A と B を入力としてGPT-4o に対して以下に示したプロンプトによって疑似経緯を生成します.このとき,N 個生成された A と B の組み合わせは N 2 個考えられます.この組み合わせごとに M個の疑似経緯が生成されるため,合計 N 2 × M 個の疑似経緯が生成されます.

Phase2: ひょんなことから要約の構成パーツおよび秘匿部に相当する事象の生成
Phase 2 の処理は, Step α とStep β から構成されています.Step α と Step β では,それぞれ疑似経緯の真実性と多様性を評価します.Step α では,M 個の擬似経緯の真実性を測るためにPhase 1 の Step 1 で生成された N 個の真の経緯との類似度を計算します.ある A と B の組み合わせから生成された疑似経緯の集合中に,真の経緯と等しいあるいは類似した経緯が存在した場合,この A と B の組み合わせから本来の物語の経緯を想起可能であるとみなすことができます.Step β では,A と B の組み合わせごとに生成された M個から成る擬似経緯集合について多様性を評価します.疑似経緯に対して,paraphrase-multilingual-MiniLM-L12- v2を用いてそれぞれ文書ベクトルを獲得し,文書ベクトルの分散を算出します.疑似経緯集合から算出された分散が大きければ,異なる内容が記述された疑似経緯が生成されていることになります.つまり,A と B は多種多様な経緯を想起させる組み合わせであると捉えられます.
Phase 3:A と B の組み合わせの決定
Phase 3 では,Phase 2 で評価した真実性と多様性の評価にもとづいて,A: 主人公属性と B: 主人公の状況/行動を決定します.Phase 2 の Step α で真実性の評価が閾値 θを超えた A と B の組み合わせの集合を Step β で多様性の評価にもとづいてソートします.真実性と多様性の評価は,AND 条件として等価に評価することや,多様性を評価した後に真実性を評価することもできます.しかし,物語の内容と異なる要約では,一見して興味喚起させたとしても読書中に羊頭狗肉を感じさせることになってしまいます.そのため,本研究では真実の経緯を想起可能であるという条件を満たしたものの中から,多様な発想を促す A と B の組み合わせを選出することとしました.
この手順を通して,ひょんなことから要約を自動で生成しました.
結果と考察
まずは,真実性の評価に関する考察です,下図は真の経緯と疑似経緯の最大類似度の分散が最も大きかった「ぬらりひょんの孫」という作品についての真の経緯と疑似経緯の組み合わせ例を各階級の相対度数とともに示したものです.生成された擬似経緯の多くは現実的な事柄が多く,創作を構成するような特徴的な物語の経緯とは特徴が異なったことに起因すると考えられます.これらの考察から,本稿では真実性の評価における閾値について,θ = 0.60 としました.

次に多様性評価に関する考察です.下図に,いくつかの作品をピックアップして Phase 2 のStep β での多様性の評価を示します.ここでは最も多様性があると判断された A:主人公属性と B:主人公の状況/行動の組み合わせと逆に最も多様性がないと判断された A:主人公属性と B:主人公の状況/行動の組み合わせを示しています.ID1の作品では,「正義感の強い」といったパーソナリティが A:主人公属性となる場合には,「水を求める」という目的が状況/行動と組み合わせられています.一方で,「水を求める」という目的を属性として扱った場合には,仲間との関係性が状況/行動となっています.またID7の例では,疑似経緯の分散が最大となった場合と最小になった場合のどちらでも A:主人公属性は「家族を支える久我一郎」でした.よってA:主人公属性それぞれに対応する B:主人公の状況/行動が異なることで,その組み合わせから想起される疑似経緯集合内での分散に差異が生まれたと考えられます.

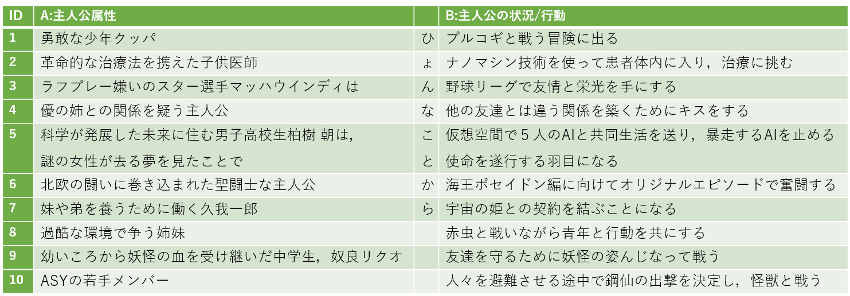
最後に提案手法によって生成されたひょんなことから要約の考察です.下図に提案手法によって生成された作品ごとのひょんなことから要約の一覧を示します. ID1,6,10 以外の作品については,作品の経緯を想起可能であり,かつ多様な経緯の可能性も想起されたと評価することが出来ました.主観評価では,ID7 が最も興味深い出力結果となりました.ID7 のAには「妹,弟,働く」という現実世界で日常的に用いる単語が出現しているのに対して,Bには「宇宙の姫,契約」など日常生活で目にする機会が少ない単語が用いられています.物語のあらすじ中での使われ方としても,A の単語は「日常,恋愛,スポーツ」,B の単語は「SF,異世界ファンタジー,近未来」で使われることが多いです.このような A:主人公属性と B:主人公の状況/行動の間のトピックやジャンルに乖離がある場合,読者の想像力を掻き立てる要因になると考えました.この乖離は,物語のジャンルごとの頻出単語などを参照することで自動的に評価できると期待しています.一方で,ID1,6,10 は固有名詞(プルコギ,ASY,鋼仙)に対する知識不足やメタ情報(海皇ポセイドン編,オリジナルエピソード)の混入によって物語の内容自体を想起することが難しかったです.今後は,他のダイジェスト要約やハイライト要約と比較して,真実性と多様性に着目したひょんなことから要約の客観評価に取り組む予定です.
おわりに
今回の研究発表では,デモ・ポスター発表に関する専門委員推薦賞を頂くことが出来ました.今回の学会ではデモ,発表の両方で多くの質問を頂くことや,議論をすることがありました.その中で聞き手の方に分かりやすく興味を持ってもらう話し方を学ぶことが出来ました.今回の研究発表を通して学んだことを今後の研究活動にも活かして取り組みます.