
はじめに
B3の橘です.2024年12月1日~3日に佐賀県唐津市の唐津商工会館で行われた.ARG 第20回Webインテリジェンスとインタラクション研究会で行った研究発表について報告させていただきます.
『LLMはTCGをプレイできるのか』というタイトルで発表しました.
研究概要
TCGの局面における最適な判断能力を評価するため,公式のルールQ&Aを用いてLLMの理解力を検証しました.実験では,RAGを活用して2種類のLLMを用意し,同一のQ&Aに解答させてその正確性を比較しました.1つは上級者向けマニュアルや公式ルールブック,カードデータベースの情報をすべて組み込んだもの,もう1つは基本的な情報のみを与えたものです.
検証に使用したQ&Aには,カードの効果処理順や特殊な状況での対応など,様々な難易度の問題を含めました.これにより,LLMがどの程度TCGのルールを理解できるのか,また与える知識の量によって解答の精度がどう変化するのかを調べました.さらに,回答の論理的な説明能力も評価し,LLMのルール理解における限界と可能性について検討を行いました.
研究背景
大規模言語モデル(LLM)は今や私たちの社会に深く浸透し,多くの知的タスクで人間と同等かそれ以上の性能を見せています.でも,人間が当たり前のように楽しんでいる「遊び」の理解となると,まだまだ課題が山積みです.AIは囲碁や将棋では人間を超えることに成功しましたが,トレーディングカードゲーム(TCG)のような複雑なルール解釈と状況判断が必要なゲームでは,どこまでできるのかまだ分かっていません.
TCGのプレイヤーは数千種類ものカードの相互作用を理解して,刻々と変わる状況で瞬時の判断を求められます.これって単なる記憶力や論理的思考だけじゃなくて,経験から培った直感的な理解も必要な高度な認知タスクなんです.しかも,ルールが自然言語で書かれていて,プレイヤー自身が解釈しないといけない.デジタルゲームみたいにプログラムが全部判定してくれるわけじゃない.こういう人間の持つすごい認知能力は,今のAIシステムにとって大きなチャレンジになっています.今回の研究では,このようなTCGの特徴に注目して,LLMの言語理解能力の限界と可能性を探っていきました.
実験
LLMのTCGルール理解能力を調べるため,2つの条件で実験を実施しました.LLMには最新のGemma2 27Bを使用し,ルールの理解を正確に評価するため英語版の公式ドキュメントを採用しました.
1つ目の条件(Basic)では基本ルールとカードデータベースだけを与え,2つ目の条件(Advanced)ではこれに上級者向けの詳しいルール解説を追加しました.評価材料として,ポケモンカードの公式FAQから100問をランダムに抽出しました.例えば「自分の山札が1枚のとき,ウェーニバルの特性『アップテンポ』を使うことはできますか?」のような質問があります.

これらの質問は,特殊な状況での処理方法,数値の計算,タイミングの判断,効果の持続時間など,7つのカテゴリに分類しました.各質問について両条件で4回ずつ回答を得て,答えと理由の正確さを0-2点で評価しました.この実験により,知識量の増加がLLMの理解力向上につながるのか,また人間の判断能力との差異はどこにあるのかを検証しました.
考察と結果 実験の結果,Basic設定(4.44点)がAdvanced設定(4.06点)を上回るという興味深い結果が得られました.両設定において得点分布の二極化が見られ,完全に理解できる場合と全く理解できない場合に分かれる傾向がありました.特にBasic設定では完全正解(8点)が34%,完全不正解(0点)が27%を占め,中間的な理解度を示すケースは比較的少ないことが分かりました.
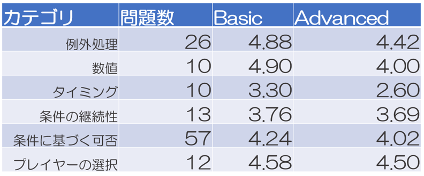
カテゴリ別の分析からは,LLMの得意・不得意が明確になりました.例外処理(Basic:4.88点)や数値計算(Basic:4.90点)では高いスコアを示しました.これは明確な判断基準があるタスクにおいてLLMが高い性能を発揮できることを示唆しています.一方で,タイミング(Basic:3.30点,Advanced:2.60点)や条件の継続性(Basic:3.76点,Advanced:3.69点)に関する質問では著しく成績が低下しました.
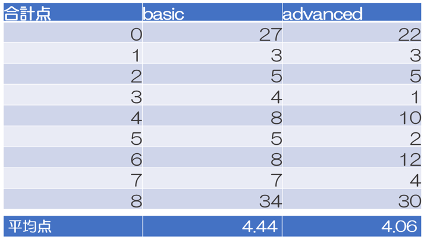
特に興味深い点は,より詳細な知識を与えたAdvanced設定でかえってスコアが低下したことです.これによって単純な知識量の増加がLLMの理解力向上に直結しないことがわかりました.むしろ,過剰な情報提供が文脈理解を妨げる可能性があることが考えられます.実験を通してLLMは状況依存的な判断や必要なルールを文脈から適切に抽出することが苦手であり,複数の要素を同時に考慮した判断も困難ということもわかりました.
人間のTCGプレイヤーは,複雑なルールの組み合わせを瞬時に理解し,状況に応じて柔軟な判断を下すことができます.これは単なる記憶や論理的思考だけでなく,経験に基づく直 感的理解と並列的な情報処理能力によって支えられています.例えば,カードの効果が発動する際,プレイヤーは瞬時に複数のルールの相互作用を考慮し,最適な処理順序を判断できます.
一方,LLMはルールの文字通りの解釈は得意としても,状況に応じた柔軟な解釈や複数のルールの組み合わせ判断が苦手でした.特にタイミングに関する質問での低スコアは,LLMが時系列的な処理順序の理解に課題を抱えていることを示しています.また,条件の継続性に関する質問でも低スコアとなり,状態の変化を追跡する能力の限界も明らかになりました.
これらの結果は,人間の認知能力の高さを改めて感じさせてくれました.今後のAI開発においては,単純な知識の蓄積だけでなく,文脈に応じた適切な知識の選択と活用,複数の情報の並列処理能力の向上が重要な課題となるでしょう.
おわりに
今回,初めて研究発表の機会をもらいショート発表を行いました.残念ながら受賞には至りませんでしたが,貴重な経験となりました.他大学の発表を見ることで自分たちのレベルを改めて把握でき,今後の研究活動へのモチベーションの増加にも繋がりました.ここで得られた経験を自分への成長二つ挙げられるよう日々努力をしていきたいと思います.